On part-1 of this series, I put a guideline list that should help detecting the non-functional requirements. Given its shocking effect, it was voted by specialized critics as a “stunning master piece of horror for this summer of 2016”, just along with Steven King’s latest book. True story.
How would the checklist help on defining the architecture of my system?
I’ll tell you a short story. It’s a transcript from a conversation a friend of a cousin of a guy that used to code had with a customer that worked on a crazy-paranoid-driven factory (they ripped movies-to-be-released on Blu-ray and DVD discs). The customer wanted the developer to finish an undone tool.
For the sake of clarity, I’ll name the developer Developer (I totally swear it was not me) and the customer just Money guy. Since picturing a conversation increases the understanding degree, I’d say this is how the Money Guy looked like:

and this is how the Developer looked like:

In an attempt to help you understanding how that checklist fits in, I’ll highlight in red the keywords that cue for requirements (both functional and non-functional).
Developer: Hi, Money Guy. Can you tell me more about this tool you want me to finish?
Money guy: Surely, Daniel Developer! There’s this very simple tool my company uses, but the previous developer just left the company, leaving some remaining work. The tool is already working, it just need to support more formats.
Developer: Formats? Is the tool some type of file reader or parser?
Money Guy: Yes, it’s a command line tool that parses a XML file and stores it into a CSV file. Nothing fancy. Is just that the XML format changed and now the tool doesn’t work (req1).
Developer: So, the tool was running perfectly fine until the file format changed?
Money guy: Oh yeah. It had run fine for the past year when it was developed (req2). It only recently stopped working. Can you fix it?
(had the conversation ended here, these would have been the known requirements so far):
| Functional |
Non-Functional |
| (req1) Add support to new XML format |
(req2) Tool is relatively new and already in production. Must not introduce breaking changes |
However, being the developer very clever, it was wise to ask more questions:
Developer: So, it was develop one year ago and…
Money guy (interrupting): Yes, probably a little bit more
Developer (continuing):… the format changed. Who is the originator of the documents?
Money guy: All of our customers, which are Hollywood studios and their distributor subsidiaries. Each file contains info about the movies they want us to rip on discs. For instance, how many copies should we rip, which regions should we restrict it to if it’s on DVD (req3), which subtitles are supported, etc. But, as you can imagine, each customer needs information that others don’t, so each one has different file formats (req4), and they change their formats very frequently! Just last month we got 3 new formats introduced (req5)

Real life Hollywood studio rep as reading this story on my blog
Developer: Does each customer has a single format? Or, can one individual customer have multiple file formats?
Money guy: Multiples. Some old products still use old formats; for example, files for DVDs usually have old formats. Now that we have also Blu-ray files, we support additional formats even if they belong to same movie (req6)
Developer: Do you support several formats simultaneously? Don’t you deprecate old ones?
Money guy: We must support all of them. Some customers still use the first file format we had (req7).
at this point, I the Developer started to see where the issue was heading to, so he had to ask:
Developer: Since you have issues with the new format, should I assume you have to modify the tool each time a new format comes?

Money guy: Yes, we have the source code and all. We must also store the extracted data into a our database, so the system that controls the production lines can read it and process it accordingly (req8)
Developer: So, this tool is part of a larger production line system?
Money guy: No; the production system is a separate corporate tool that all sites must use. They never gave us the code, which was causing us to manually update the system config each time there was a new format. We eventually figured it out on how to insert data directly into their DB to avoid this work.
Developer: You had mentioned the tool would export to CSV, but now you mention it inserts into a DB??

Money guy: It will insert into a DB, and the DB exports to CSV. We need the DB because it contains a lot of data that need to be part of the final CSV (req9).
Developer: Does this tool run on Windows? Linux? Or which OS?
Money guy: It’s a scheduled task that runs on Windows XP workstation every 5 minutes (req10).
Developer: And which is the database engine? Where is it located?
Money guy: It’s actually a web service (req11) we call (it wasn’t), but we know for sure it is the web service what inserts into the DB (it wasn’t).
By this shallow conversation, the requirements were now:
| Functional |
Non-Functional |
| (req1) Add support to new XML format
(req3) Each product can have different formats
(req4) Each customer has its own custom fields |
(req2) Tool is relatively new and already in production. Must not introduce breaking changes
(req5) The formats can change very quickly
(req6) Formats cannot be easily normalized even for the similar products
(req7) Must support format versioning
(req8, req11) Must interact with another system
(req9) Complementary data is retrieved from a different database
(req10) Files can be dropped at anytime and must be processed ASAP |
As your 6th sense might be telling you, in real life it took much longer than an informal conversation to gather a lot more requirements; when the Developer was finally granted access to the source control management system computer behind a cube with code, this is how it looked (after finding the “XmlTool3-Rev14-Final2-Good” folder):

I won’t bother you with more details on this, but I can tell you some key points:
- The tool was never intended to support all this myriad of file formats, and they were letting their customers to define their own files instead of having a standard B2B template that covered all needs.
- After negotiating with their customers, they agreed on using the standard template which, in turn, simplified the entire architecture of the tool. Two customers didn’t want to change their files, and
we The Developer simply decided to use an intermediate XSLT to transform the non-standard XML into the standard one, then process it with the tool as usual.
- For the database stuff, the Developer made the tool to perform the required insertions, grab the generated IDs back and make the tool to generate the CSV. That way the DB remained being a storage mechanism, not a file processor.
- The entire tool ended up being a robust Windows service with XSLT transformations, non-blocking queues, etc
So, what had failed on the original version?
Easy: The architecture was done from the perspective of “getting things done”. The original developer took the requirements of a parsing tool from the customer, coded it and deployed it. He never analyzed it from a solution perspective. He never considered the fast-pace of Hollywood industry, the quick turnaround in a manufacturing company, the amount of new studios emerging every day with new requirements each, the universe of export-compliance rules for different countries, etc.
When all these changes started coming and the tool could not be adapted fast-enough, the developer ended-up patching the tool everywhere and, eventually, quitting since he got burnt-out.
Had the original developer focused more on offering a solution to a business-to-business-need (on the what and why), instead of offering a tool to a concrete way of exchanging data (on the how), the entire architecture approach would have been different.
How to build a robust system, yet prevent over-engineering?
That is a perfectly valid question. To answer it, I’ll share with you my own software architecture manifesto. You will be able to view it on part 3.



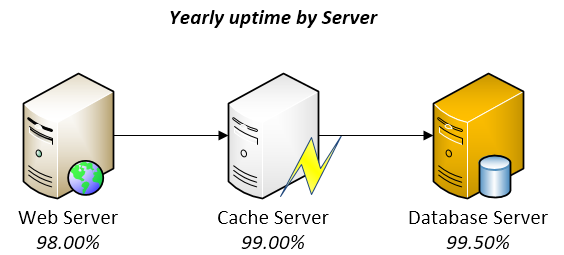
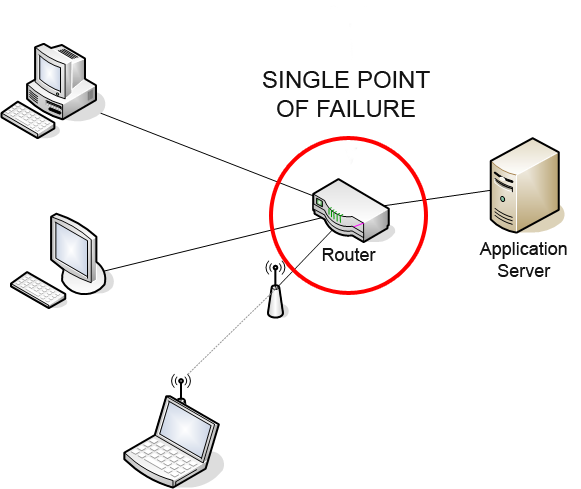
 A Disaster-Recovery plan is a set of artifacts, e.g. documents, scripts, servers, contact names, tape backups, that will be used to restore services after a wide range of catastrophic events such as “all servers got corrupted” or “a
A Disaster-Recovery plan is a set of artifacts, e.g. documents, scripts, servers, contact names, tape backups, that will be used to restore services after a wide range of catastrophic events such as “all servers got corrupted” or “a 






{kind=link}
{kind=link}
You must be logged in to post a comment.